Программирование: введение в профессию. 1: Азы программирования - 2016 год
Ещё об оформлении программ - Язык Паскаль и начала программирования
Если бы строители строили дома так, как программисты пишут программы,
то первый залетевший дятел разрушил бы цивилизацию.
Второй закон Вайнберга
Мы уже неоднократно обращали внимание читателя на то, что текст программы нельзя писать как попало: он предназначается в первую очередь для прочтения человеком, и лишь во вторую — для компилятора, и если об этом забыть, то в вашей программе не только другие люди ничего не поймут, но и, что особенно обидно, вы рискуете сами заблудиться в собственной программе, не успев её дописать.
Для повышения понятности и читаемости программы существует ряд простых, но очень важных правил. В частности, мы уже знаем, что вложенные фрагменты следует сдвигать вправо относительно того, во что они вложены, а строки, начинающие и заканчивающие любую конструкцию, должны начинаться в одной и той же горизонтальной позиции. При этом размер сдвига вправо, называемого также структурным отступом, может составлять два пробела, три пробела, четыре пробела или один символ табуляции; вы можете выбрать любой из этих четырёх вариантов, но затем придерживаться избранного варианта во всей вашей программе. Заметим, что все примеры программ в этой книге набраны с использованием отступа в четыре пробела.
Мы также уже знаем, что существует три допустимых варианта расположения операторных скобок (для Паскаля это слова begin и end). Во всех программах на Паскале, приведённых в этой части книги, мы всегда сносили слово begin на следующую строку после заголовка оператора (while или if), при этом писали его, начиная с той же позиции, где начинается сам заголовок, то есть мы не делали отдельного сдвига для операторных скобок (рис. 2.15, слева). Наряду с этим, допустимы ещё два стиля. Слово begin можно оставить на одной строке с заголовком оператора, при этом end располагается точно под началом оператора (а не под словом begin!), как это показано на том же рисунке в середине; именно так будут оформлены программы на Си в соответствующих частях нашей книги. Наконец, можно begin снести на следующую строку, но при этом предусмотреть для операторных скобок отдельный сдвиг (на рисунке этот вариант показан справа). При использовании последнего варианта обычно выбирают размер отступа в два пробела, потому что иначе горизонтальное пространство на экране очень быстро исчерпывается; как уже говорилось, этот вариант допустим, но рекомендовать его мы не станем.
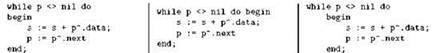
Рис. 2.15. Три стиля расположения операторных скобок
2.15.1. Оператор if с веткой else
В Паскале оператор ветвления можно использовать как в полном варианте с веткой else, так и в сокращённом — без неё. Если ветка else отсутствует, то с оформлением текста конструкции всё понятно; никакой свободы нам не оставляет также и случай, когда обе ветки присутствуют, но состоят из одного простого оператора, то есть не требуют использования операторных скобок:
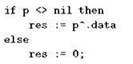
Нужно только не забывать, что тело всегда следует размещать на отдельной строчке, и в случае оператора if это касается обеих ветвей. Так, следующий вариант недопустим:
![]()
![]()
Рассмотрим теперь случай, когда обе ветви оператора if используют составной оператор. В этой ситуации нужно прежде всего вспомнить, какой из трёх допустимых вариантов размещения открывающей операторной скобки мы в итоге выбрали. Если наш выбор пал на первый или третий вариант (в обоих случаях открывающая операторная скобка сносится на следующую строку), то всё достаточно просто. Если мы решили не сдвигать скобки составного оператора, а сдвигать только его тело, if придётся оформить так:

Собственно говоря, именно так мы и оформляли ветвление в наших примерах. Если же вы, невзирая на все наши старания, избрали вариант со сдвигом операторных скобок, то if будет выглядеть так:
В обоих случаях else вместе со скобками занимает три строки, что, по мнению многих программистов, многовато для разделителя. Если же открывающая операторная скобка оставляется на одной строке с заголовком, то в этом случае для ветки else также остаётся два варианта, а именно поместить слово else на одной строке с закрывающей операторной скобкой или же писать elseс новой строки:

Рассмотрим теперь случай, когда только одна ветка конструкции if-else требует использования составного оператора, тогда как вторая состоит из одного простого оператора. Если принято решение сносить открывающую операторную скобку на следующую строку (не важно, со сдвигом или без), то этот случай не является особым к не требует отдельного рассмотрения. Можно было бы вообще не рассматривать этот случай в качестве специального, но результаты могут получиться несколько неэстетичные (в программах на Паскале это не столь заметно, но очень заметно, если мы пишем на Си). В связи с этим можно дать следующую рекомендацию: если одна ветвь конструкции if-else представляет собой составной оператор, то для второй следует также использовать составной оператор, даже если она состоит из одного простого оператора. Отметим, что следование этой рекомендации, вообще говоря, факультативно; больше того, как можно заметить, мы в наших примерах так не делали — но обязательно будем так делать, когда доберёмся до изучения Си.
2.15.2. Особенности оформления оператора выбора
Язык Паскаль не предполагает в составе оператора выбора (case) использование слова begin, хотя предполагает слово end, так что оформление заголовка и тела оператора выбора не зависит от того, оставляем ли мы открывающую операторную скобку на одной строке с заголовком сложного оператора, сносим ли мы её на следующую строку и снабжаем ли мы её своим собственным отступом; с другой стороны, в большинстве случаев в каждой ветке приходится использовать составные операторы, а их оформление уже зависит от избранного стиля.
В любом случае потребуется ответить ещё на один вопрос: будете ли вы сдвигать метки относительно самого оператора; метки, обозначающие начало очередной альтернативы в операторе выбора, можно либо оставлять в той колонке, где начинается заголовок оператора выбора, либо сдвинуть относительно заголовка на размер отступа. Как обычно в таких случаях, вы можете выбрать любой из двух вариантов, но только один раз — на всю программу.
Если мы оставляем операторную скобку на одной строке с заголовком, то в зависимости от выбранного стиля размещения меток мы можем написать так:

Отметим, что, хотя оба варианта являются допустимыми, первый выглядит существенно привлекательнее и понятнее, так что если мы оставляем операторную скобку па одной строке с заголовком, будет лучше принять решение в пользу сдвигания меток.
Если мы условились сносить операторную скобку на следующую строку, но не сдвигать её, вышеприведённый фрагмент кода должен выглядеть так:

Для этого случая мы также порекомендуем сдвигать метки (мы именно так и делали в наших примерах), но окончательное решение оставим за читателем.
Наконец, если мы не только сносим операторную скобку, но и сдвигаем её, то выглядеть это будет приблизительно так:

Для этого случая наша рекомендация будет противоположной: если операторные скобки имеют свой собственный сдвиг, то метки лучше не сдвигать, результат будет эстетичнее.
2.15.3. Метки и оператор goto
Мы уже знаем из § 2.6.3, что goto использовать в некоторых случаях не только можно, но и нужно; более того, мы точно знаем, какие это случаи; повторим ещё раз, этих случаев ровно два, и третьего нет. Остаётся ответить на вопрос, как всё это оформлять. Точнее, сам оператор goto никаких проблем с оформлением не вызывает, это обыкновенный оператор, оформляемый по обычным правилам; но вот то, как следует ставить метку, может стать предметом жаркой дискуссии.
Напомним, что меткой всегда помечается оператор, то есть, даже если мы пометим меткой “пустое место”, компилятор будет считать, что там располагается пустой оператор. Вопросов, на которые нужно дать (зафиксировать) ответ, оказывается два: сдвигать ли метку относительно объемлющей конструкции (отметим, что с аналогичной дилеммой мы уже встречались при обсуждении операторов выбора в § 2.15.2) и размещать ли помеченный оператор на той же строке, где метка, или на отдельной.
Наиболее популярен вариант, при котором метка не сдвигается, то есть пишется в той же горизонтальной позиции, в которой размещены начало и конец объемлющей управляющей структуры, а помеченный оператор сносится на следующую строку, например:

Метка здесь оказалась в крайней левой позиции исключительно потому, что именно там размещается объемлющая структура (в данном случае это подпрограмма). Метка может встретиться и не на верхнем уровне, например:

Приведённый вариант наиболее популярен, но это не единственный допустимый вариант. Довольно часто оператор, помеченный меткой, пишут в той же строке, что и метку, примерно так:
Этот вариант неплохо смотрится, если метка — вместе с двоеточием и пробелом после него — занимает по горизонтали меньше места, чем выбранный размер отступа, что позволяет выдержать горизонтальное выравнивание для операторов:
Поскольку имя метки из одной буквы само по себе выглядит не слишком приятно, обычно такой стиль применяют в сочетании с отступами в табуляцию (максимальная длина имени метки при этом составляет 6 символов).
Некоторые программисты предпочитают рассматривать метку просто как часть помеченного оператора, не выделяя её как особую сущность; оператор сдвигают как обычно, но на этот раз уже вместе с меткой. Концовка вышеприведённых подпрограмм в таком стиле будет выглядеть так:
Иногда метку сдвигают, но помеченный оператор сносят на следующую строку, примерно так:
Основной недостаток таких решений — метка сливается с окружающим “пейзажем”, перестаёт быть заметна в качестве особой точки в структуре кода; возьмём на себя смелость рекомендовать воздержаться от такого стиля, но, тем не менее, сохраним решение за читателем.
2.15.4. Максимальная ширина текста программы
Thou shalt not cross 80 columns in thy file47.
(The sacred 80 column rule)
Традиционная в программировании ширина текста составляет 80 символов. Происхождение числа 80 восходит ко временам перфокарт; перфокарты наиболее популярного формата, предложенного фирмой IBM, содержали 80 колонок для пробивания отверстий, причём при использовании этих карт для представления текстовой информации каждая колонка задавала один символ. Одна перфокарта, таким образом, содержала строку текста до 80 символов длиной, и именно из таких строк состояли тексты компьютерных программ тех времён. Длина строки текста, равная 80 символам, ещё в начале 1990-х годов оставалась одним из стандартов для матричных принтеров. При появлении в начале 1970-х алфавитно-цифровых терминалов их ширина составила 80 знакомест, чтобы обеспечить совместимость двух принципиально различных способов ввода компьютерных программ. До сих пор многие компьютеры, оснащённые дисплеями, после включения питания начинают работу в текстовом режиме, и лишь после загрузки операционной системы переключаются в графический режим; ширина экрана в текстовом режиме в большинстве случаев составляет всё те же 80 знакомест.
Одним из традиционных способов управления компьютером остаётся хорошо знакомая нам командная строка; чаще всего для этого используются графические программы, эмулирующие алфавитно-цифровой терминал. Ширина строки в таких программах по умолчанию составляет, как несложно убедиться, 80 символов, хотя это обычно легко исправить, просто изменив размеры окна.
Было бы неверно полагать, что число 80 здесь абсолютно случайно. Если ограничение на длину строк сделать существенно меньшим, писать программы станет неудобно, в особенности когда речь идёт о структурированных языках, в которых необходимо использование структурных отступов; так, в ширину 40 символов не уложатся даже самые простенькие программы. С другой стороны, программы с существенно более длинными строками тяжело читать, даже если соответствующие строки помещаются на экране или листе бумаги. Причина здесь сугубо эргономическая и связана с необходимостью постоянно переводить взгляд влево-вправо; отметим, что в большинстве книг ширина полосы набора также не превышает 80 символов (обычно книжная строка вмещает 65-75 знаков). Традиция ограничивать длину строк текста 80 символами насчитывает столь долгую историю48 именно потому, что число 80 представляет собой удачный компромисс между малой вместительностью коротких строк и неудобочитаемостью длинных, и этот компромисс, что в данном случае важно, был известен издателям книг задолго до компьютерной эры.
При современном размере дисплеев, их графическом разрешении и возможности сидеть к ним близко без вреда для здоровья многие программисты не видят ничего плохого в редактировании текста при ширине окна, существенно превышающей 80 знакомест. С точки зрения эргономики такое решение не вполне удачно; целесообразно либо сделать шрифт крупнее, чтобы глаза меньше уставали, либо использовать ширину экрана для размещения нескольких окон с возможностью одновременного редактирования разных файлов — это сделает более удобной навигацию в вашем коде, ведь код сложных программ обычно состоит из множества файлов, и вносить изменения часто приходится одновременно в несколько из них. Отметим, что многие оконные текстовые редакторы, ориентированные на программирование, такие как geany, gedit, kate и т. п., штатно показывают на экране линию правой границы — как раз на уровне 80-го знакоместа.
Немалое число программистов предпочитает не распахивать окно текстового редактора шире, чем на 80 знакомест; более того, многие программисты пользуются редакторами текстов, работающими в эмуляторе терминала, такими, как vim или emacs; оба редактора имеют графические версии, но не всем программистам эти версии нравятся. Довольно часто в процессе эксплуатации программы возникает потребность просматривать и даже редактировать исходные тексты на удалённой машине, при этом качество связи (либо политика безопасности) может не позволять использование графики, и тогда окно алфавитно-цифрового терминала становится единственным доступным инструментом. Известны программные средства, предназначенные для работы с исходными текстами программ (например, выявляющие различия между двумя версиями одного и того же исходного текста), которые реализованы в предположении, что строки исходного текста не превышают 80 символов в длину.
Часто листинг программы бывает нужно напечатать на бумаге. Наличие длинных строк в такой ситуации поставит вас перед неприятным выбором. Можно заставить длинные строки умещаться на бумаге в одну строчку — либо уменьшив размер шрифта, либо используя более широкий лист бумаги или “пейзажную” ориентацию — но при этом большая часть площади листа бумаги останется пустой, а читать такой листинг будет труднее; если строки обрезать, попросту отбросив несколько правых позиций, есть риск упустить что-то важное; наконец, если заставить строки автоматически переноситься, читаемость полученного бумажного листинга будет хуже, нежели читаемость исходного текста с экрана, что уже совсем никуда не годится.
Вывод из всего вышесказанного напрашивается довольно очевидный: каким бы текстовым редактором вы ни пользовались, не следует допускать появления в программе строк, длина которых превосходит 80 символов. В действительности желательно всегда укладываться в 75 символов, что позволяет уместить в 80 символов не только строку исходного кода, но и её номер (четыре символа на номер, одно знакоместо на пробел между номером и собственно строкой, оставшиеся позиции на текст). Это позволит комфортно работать с вашим текстом, например, программисту, использующему редактор vim с включённой нумерацией строк; из такого исходного кода можно будет сформировать красивый и легко читаемый листинг с пронумерованными строками. Как уже говорилось, редакторы текстов, ориентированные на программирование, обычно поддерживают изображение правой границы и по умолчанию отображают её именно после 80-го знакоместа в строке; не пренебрегайте этим.
Некоторые руководства по стилю оформления кода допускают “в исключительных случаях” превышать предел длины строки. Например, стиль оформления, установленный для ядра ОС Linux, категорически запрещает разносить на несколько строк текстовые сообщения, к для этого случая говорится, что лучше будет, если строка исходного текста “вылезет” за установленную границу. Причина такого запрета вполне очевидна. Ядро Linux — программа крайне обширная, и ориентироваться в её исходных текстах довольно трудно. Часто в процессе эксплуатации возникает потребность узнать, какой именно фрагмент исходного текста стал причиной появления того или иного сообщения в системном журнале, и проще всего найти соответствующее место простым текстовым поиском, который, разумеется, не сработает, если сообщение, которое мы пытаемся найти, разнесено на несколько текстовых констант, находящихся в разных строках исходника.
Тем не менее, превышение допустимой длины строк остаётся нежелательным. В том же руководстве по оформлению кода для ядра Linux на этот счёт имеются дополнительные ограничения — так, за правой границей экрана не должно быть “ничего существенного”, чтобы человек, бегло просматривающий программу и не видящий текста справа от границы, не пропустил какое-то важное её свойство. Чтобы определить, насколько допустим ваш случай, может потребоваться серьёзный опыт. Поэтому наилучшим вариантом будет всё же считать требование соблюдения 80-символьной границы жёстким, то есть не допускающим исключений; как показывает практика, с этим всегда можно справиться, удачно разбив выражение, сократив текстовое сообщение, уменьшив уровень вложенности путём вынесения частей алгоритма во вспомогательные подпрограммы.
Кроме стандартной ширины экрана, следует обратить внимание также и на его высоту. Как уже говорилось выше, подпрограммы следует по возможности делать небольшими, чтобы они помещались на экран по высоте; остаётся вопрос, какой следует предполагать эту “высоту экрана”. Традиционный ответ на этот вопрос — 25 строк, хотя имеются и вариации (например, 24 строки). Предполагать, что экран будет больше, не следует; впрочем, как уже говорилось, длина подпрограммы в некоторых случаях имеет право слегка превышать высоту экрана, но не намного.
2.15.5. Как разбить длинную строку
Коль скоро мы решили не выходить за 80 колонок, логично возникает вопрос: что же делать, если очередная строка программы никак не хочет в этот лимит укладываться. Начнём с обсуждения случая, когда слишком длинным оказался заголовок оператора (if, while или case).
Прежде всего следует подумать, нельзя ли подсократить условное выражение. Во многих случаях длинные выражения в заголовках структурных операторов возникают в силу недостатка опыта программиста; так, автор часто видел в студенческих программах проверку принадлежности символа к тому или иному множеству (например, множеству знаков препинания) через последовательность явно прописанных сравнений с каждым из элементов множества, что-то вроде:
![]()
Разумеется, здесь никакой проблемы с недостатком места в строке на самом деле нет, есть лишь проблема недостаточности воображения. Программист, миновавший стадию новичка, в такой ситуации опишет функцию, проверяющую принадлежность заданного символа предопределённому множеству, а заголовок if’а будет содержать вызов этой функции:
![]()
Более опытный программист воспользуется готовой функцией из стандартной библиотеки, а ещё более опытный, возможно, заявит, что стандартная функция чрезмерно сложна, поскольку зависит от настроек локали в окружении, и вернётся к варианту со своей собственной функцией. Так или иначе, никакой проблемы с длиной заголовка тут нет.
К сожалению, не всегда проблемы решаются так просто. Многострочные заголовки, как бы мы ни пытались их побороть, всё равно иногда в программе возникают. Однозначного ответа, как с ними поступить, к сожалению, нет; мы рассмотрим один из возможных вариантов, который нам представляется наиболее практичным и отвечающим поставленной задаче читаемости программы.
Итак, если заголовок сложного оператора приходится разнести на несколько строк, то:
• разбейте выражение в заголовке на несколько строк; предпочтительно разрывать строку по “операции верхнего уровня”, это обычно логическая связка “и” либо “или”;
• каждую последующую строку заголовка сдвиньте относительно первой строки заголовка на обычный размер отступа;
• вне зависимости от количества простых операторов в теле, обязательно возьмите тело вашего оператора в операторные скобки, то есть сделайте его составным оператором;
• вне зависимости от используемого стиля, снесите открывающую операторную скобку на следующую строку, чтобы она послужила зрительным разделителем между строками заголовка и строками тела вашего оператора.
Всё вместе будет выглядеть примерно так:
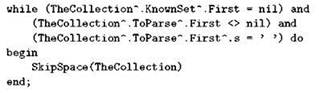
Такой вариант нормально сработает, если вы не сдвигаете составной оператор относительно заголовка; если же вы предпочли именно этот (“третий”) стиль оформления, можно посоветовать снести на следующую строку слово then, do или of, примерно так:

Роль зрительного разделителя здесь играет завершающее слово из заголовка.
Если вы используете стиль, при котором открывающая операторная скобка оставляется на одной строке с заголовком, вы можете воспользоваться ещё одним вариантом форматирования: как в предыдущем примере, снесите последнюю лексему заголовка на отдельную строку, и на этой же строке оставьте открывающую операторную скобку:
Такой стиль нравится не всем, но вы и не обязаны ему следовать; даже если везде вы оставляете операторную скобку на строке заголовка, для многострочного заголовка вы вполне можете сделать исключение и оформлять его так, как показано в первом примере этого параграфа.
Рассмотрим другие ситуации, когда строка может не поместиться в отведённое горизонтальное пространство. Хотелось бы сразу заметить, что лучший способ справиться с такими ситуациями — это не допускать их. Часто руководства по стилю оформления кода пишутся в предположении, что программист всегда может избежать нежелательной ситуации, и там попросту не говорится о том, что же нужно делать, если ситуация всё-таки сложилась; такое умолчание приводит к тому, что программисты начинают выходить из положения как попало, причём часто даже разными способами в рамках одной программы. Во избежание этого мы приведём несколько примеров того, как можно действовать, если длинная строка никак не хочет становиться короче.
Допустим, слишком длинное выражение встретилось в правой части присваивания. Первое, что мы посоветуем — это попытаться разбить строку по знаку присваивания. Если слева от присваивания стоит что-то достаточно длинное, такой вариант вполне может помочь, например:
![]()
Обратите внимание, что выражение, стоящее справа от присваивания, мы не просто снесли на следующую строку, но и сдвинули вправо на размер отступа. Если после этого выражение по-прежнему не помещается на экран, можно начать разбивать и его, и делать это лучше всего по знакам операций наименьшего приоритета, например:

Может получиться так, что даже после этого экран останется слишком узким для вашего выражения. Тогда можно попытаться начать разбивать на несколько строк подвыражения, входящие в ваше выражение; их части нужно, в свою очередь, сдвинуть ещё на один отступ, чтобы выражение более-менее легко читалось, насколько вообще возможно для такого монструозного выражения говорить о лёгкости прочтения:

Если выражение состоит из большого количества подвыражений верхнего уровня (например, слагаемых), которые сами по себе не очень длинны, вполне допустимо оставлять несколько таких подвыражений в одной строке:
![]()
Конечно, если в реальности вам пришлось вот так сложить 26 переменных, то это повод задуматься, почему вы не используете массив; здесь мы приводим сумму простых переменных исключительно для иллюстрации, в реальной жизни вместо переменных у вас будет что-то более сложное.
Отдельного обсуждения заслуживает ситуация, когда слева от присваивания стоит простое имя переменной или даже выражение, но короткое, так что разбивка строки по знаку присваивания не даёт никакого (или почти никакого) выигрыша. Естественно, выражение справа от присваивания по-прежнему лучше всего разбивать по операциям низшего приоритета; вопрос лишь в том, с какой позиции начинать каждую следующую строку. Ответов на этот вопрос ровно два: каждую следующую строку можно либо сдвигать на один отступ, как в примерах выше, либо размещать её начало точно под началом выражения в первой строке нашего присваивания (сразу после знака присваивания). Сравните, вот пример первого варианта:
![]()
А вот так тот же код будет выглядеть, если выбрать второй вариант:
![]()
Оба варианта допустимы, но имеют существенные недостатки. Первый вариант заметно проигрывает второму в ясности, но второй вариант требует для второй и последующих строк нестандартного размера отступа, который оказывается зависящим от длины выражения слева от присваивания. Отметим, что этот (второй) вариант совершенно не годится, если вы используете в качестве отступа табуляцию, потому что добиться такого выравнивания можно только пробелами, а смешивать пробелы и табуляции не следует ни в коем случае.
Если недостатки обоих вариантов кажутся вам существенными, вы можете взять себе за правило всегда переводить строку после знака присваивания, если весь оператор целиком не поместился на одну строку. Такой вариант (рассмотренный в начале параграфа) свободен от обоих недостатков, но требует использования лишней строки; впрочем, запас строк во Вселенной неограничен. Выглядеть это будет так:

Следующий случай, требующий рассмотрения — это слишком длинный вызов подпрограммы. Если при обращении к процедуре или функции у вас не помещаются в одну строку параметры, то строку, естественно, придётся разорвать, и обычно это делают после очередной запятой, отделяющей параметры друг от друга. Как и в случае с разбросанным по нескольким строкам выражением, возникает вопрос, с какой позиции начать вторую и последующие строки, и вариантов тоже два: сдвинуть их либо на размер отступа, либо так, чтобы все параметры оказались записаны “в столбик”. Первый вариант выглядит примерно так:
![]()
Второй вариант для приведённого примера будет выглядеть так:
Отметим, что это вариант, как и аналогичный вариант форматирования выражений, не годится при использовании табуляции в качестве размера отступа: добиться такого выравнивания можно только пробелами, а смешивать пробелы и табуляции не следует.
Если оба варианта вам по тем или иным причинам не понравились, мы можем предложить ещё один вариант, который используется очень редко, хотя и выглядит вполне логичным: рассматривать имя подпрограммы и круглые скобки в качестве объемлющей конструкции, а параметры — в качестве вложенных элементов. В этом случае наш пример будет выглядеть так:

Часто бывает так, что слишком длинным оказывается заголовок подпрограммы. В этой ситуации следует прежде всего внимательно рассмотреть возможности его сокращения, при этом допуская, в числе прочего, вариант с изменением разбивки кода на подпрограммы. Как уже говорилось, подпрограммами с шестью и более параметрами очень тяжело пользоваться, так что, если причиной “распухания” заголовка оказалось большое количество параметров, следует подумать, нельзя ли так изменить вашу архитектуру, чтобы это количество сократить (возможно, ценой появления большего количества подпрограмм).
Следующее, на что нужно обратить внимание — это имена (идентификаторы) параметров. Поскольку эти имена локальны для вашей подпрограммы, их вполне можно сделать короткими, вплоть до двух-трёх букв. Конечно, при этом мы лишаем эти имена самопоясняющей силы, но заголовок подпрограммы в любом случае обычно снабжают комментарием, хотя бы коротким, и соответствующие пояснения о смысле каждого параметра можно вынести в этот комментарий.
Бывает, что даже после всех этих ухищрений заголовок по-прежнему не помещается в 79 знакомест. Скорее всего, придётся разнести на разные строки список параметров, но прежде чем это делать, стоит попытаться убрать на отдельные строки начало и конец заголовка. Так, можно написать на отдельной строке слово procedure или function (следующая строка при этом не сдвигается!). Кроме того, тип возвращаемого значения функции, указанный в конце заголовка, также можно снести на отдельную строку вместе с двоеточием, но эту строку следует сдвинуть так, чтобы тип возвращаемого значения оказался где-то под концом списка параметров (даже если вы используете табуляции). Дело в том, что читатель вашей программы именно там (где-то справа) ожидает увидеть тип возвращаемого значения, и на то, чтобы отыскать его на следующей строчке слева, а не справа, читателю придётся потратить лишние усилия. Всё вместе может выглядеть примерно так:
![]()

Если это не помогло и заголовок по-прежнему слишком длинный, остаётся только один вариант — разбить на части список параметров. Естественно, переводы строк вставляются между описаниями отдельных параметров. Если при этом несколько параметров имеют один тип и перечислены через запятую, желательно оставить их на одной строке, а разрывы строк помещать после точки с запятой, стоящей после имени типа. В любом случае, остаётся вопрос относительно горизонтального размещения (сдвига) второй и последующих строк. Как и для рассмотренных выше случаев длинного выражения и длинного вызова подпрограммы, здесь есть три варианта. Во-первых, можно начать список параметров на одной строке с именем подпрограммы, а последующие строки сдвинуть на размер отступа. Во-вторых, можно начать список на одной строке с именем подпрограммы, а последующие строки сдвинуть так, чтобы все описания параметров начинались в одной и той же позиции (этот случай не годится, когда для форматирования используется табуляция). Наконец, можно, рассматривая имя подпрограммы и открывающую скобку как заголовок сложной структуры, снести описание первого параметра на следующую строку, сдвинув его на размер отступа, остальные параметры разместить под ним, а круглую скобку, закрывающую список параметров, разместить на отдельной строке в первой позиции (под началом заголовка).
Несколько особняком стоит в нашем списке случай длинной строковой константы. Конечно, самое худшее, что можно сделать — это “заэкранировать” символ перевода строки, продолжив строковый литерал в начале следующей строчки кода. Не делайте так никогда:
![]()
![]()
В Паскале благодаря операции сложения строк можно сделать так:
![]()
Но и это не вполне правильно. Единое текстовое сообщение, выдаваемое как одна строка (т. е. не содержащее символов перевода строки среди выдаваемого текста), вообще лучше не разносить на разные строки кода. Остаётся попробовать ещё два способа борьбы с длиной строкового литерала.
Во-первых, как это ни банально, стоит подумать, нельзя ли сократить содержащуюся в строке фразу без потери смысла. Как известно, краткость — сестра таланта. Например, для рассматриваемого примера возможен такой вариант:
![]()
Смысл английской фразы мы оставили прежним, но теперь она, вопреки собственному содержанию, вполне нормально помещается в строке кода.
Во-вторых (если сокращать ничего не хочется), можно заметить, что некоторые строковые константы уместились бы в строке кода, если бы содержащий их оператор начинался в крайней левой позиции, т. е. если бы не структурный отступ. В такой ситуации справиться с упрямой константой совсем легко: достаточно дать ей имя — например, описать в виде константы:

К сожалению, бывает и так, что ни один из перечисленных способов не помогает. Тогда остаётся лишь последовать правилам из Linux Kernel Coding Style Guide и оставить в коде строку, длина которой превышает 80 символов. Следите только, чтобы это превышение не выходило за грань разумного. Так, если получившаяся строка кода “вылезла” за 100 символов, и при этом вам кажется, что ни одним из вышеперечисленных способов побороть зловредную константу нельзя, то это вам, скорее всего, только кажется; автор этих строк ни разу за всю свою практику не видел ситуации, в которой строковую константу нельзя было бы уместить в обычные 80 символов, не говоря уже о ста.
2.15.6. Пробелы и разделители
Знаки, которые в тексте программы выделяются в отдельные лексемы независимо от наличия или отсутствия вокруг них пробельных символов, называются разделителями. Обычно это знаки арифметических операций, скобки и знаки препинания, такие как запятая, точка с запятой и двоеточие. Например, операции + и - являются разделителями, поскольку можно написать а + b, а можно и а+b, смысл от этого не изменится. В то же время операция and разделителем не является: a and b — это не то же самое, что aandb.
Несмотря на то, что пробельные символы вокруг разделителей не обязательны, в ряде случаев их добавление может сделать текст программы более эстетичным и читаемым — но не всегда. При этом, как водится, невозможно предложить единый универсальный свод правил по поводу расстановки таких пробелов; существуют различные подходы, имеющие свои достоинства и недостатки. С уверенностью можно сказать, что для знаков препинания — запятых, точек с запятой и двоеточий — лучше всего подходит одно простое правило: перед ними пробелы не ставятся, а после них — наоборот, ставятся (это может быть, как собственно пробел, так и перевод строки).
Некоторые программисты ставят пробелы с внутренней стороны скобок (круглых, квадратных, фигурных и угловых), примерно так:
![]()
Мы не рекомендуем так делать, хотя это и допустимо; лучше написать так:
![]()
При обращении к процедурам и функциям пробел между именем вызываемой подпрограммы и открывающей скобкой обычно не ставят, так же как и пробел между именем массива и открывающей квадратной скобкой операции индексирования.
Несколько особняком стоит вопрос о том, какие из арифметических операций следует выделять пробелами, и как (с одной стороны или с обеих). Одна из самых популярных и при этом внятных рекомендаций звучит так: символы бинарных операций выделяются пробелами с обеих сторон, символы унарных операций пробелами не выделяются. При этом следует учитывать, что операции выборки поля из сложной переменной (точка в Паскале и Си, “стрелка” в Си) бинарными не являются, поскольку справа у них не операнд, а название поля, которое не может быть значением выражения. Подчеркнём, что такой стиль является наиболее популярным, но никоим образом не единственным; возможно следование совсем другим правилам, например — в любом выражении выделять пробелами бинарные операции наименьшего приоритета (то есть операции самого “верхнего” уровня), а остальные пробелами не выделять, и т. д.
2.15.7. Выбор имён (идентификаторов)
Общее правило при выборе имён достаточно очевидно: идентификаторы следует выбирать в соответствии с тем, для чего они используются. Некоторые авторы утверждают, что идентификаторы всегда обязаны быть осмысленными и состоять из нескольких слов. На самом деле, это не всегда так: если переменная исполняет сугубо локальную задачу и её применение ограничено несколькими строчками программы, имя такой переменной вполне может состоять из одной буквы. В частности, целочисленную переменную, играющую роль переменной цикла, чаще всего называют просто “i”, и в этом нет ничего плохого. Но однобуквенные переменные уместны только тогда, когда из контекста однозначно (и без дополнительных усилий на анализ кода) понятно, что это такое и зачем оно нужно, ну и ещё, пожалуй, разве что в тех редких случаях, когда переменная содержит некую физическую величину, традиционно обозначаемую именно такой буквой — например, температуру вполне можно хранить в переменной t, а пространственные координаты — в переменных х, у и z. Указатель можно назвать р или ptr, строку — str, переменную для временного хранения какого-то значения — tmp; переменную, значение которой будет результатом вычисления функции, часто называют result или просто res, для сумматора вполне подойдёт лаконичное sum и так далее.
Важно понимать, что подобные лаконичности подходят лишь для локальных идентификаторов, то есть таких, область видимости которых ограничена — например, одной подпрограммой. Если же идентификатор виден во всей программе, он просто обязан быть длинным и понятным — хотя бы для того, чтобы не возникало конфликтов с идентификаторами из других подсистем. Чтобы понять, о чём идёт речь, представьте себе программу, над которой работают два программиста, и один из них имеет дело с температурным датчиком, а другой — с часами; как температура, так и время традиционно обозначаются буквой t, но если наши программисты воспользуются этим обстоятельством для именования глобально видимых объектов, то проблем не миновать: программа, в которой есть две разные глобальные переменные с одним и тем же именем, не имеет шансов пройти этап компоновки.
Более того, когда речь идёт о глобально видимых идентификаторах, сама по себе длина и многословность ещё не гарантирует отсутствия проблем. Допустим, нам потребовалось написать функцию, которая опрашивает датчик температуры и возвращает полученное значение; если мы назовём её GetTemperature, то формально вроде бы всё в порядке, на самом же деле с очень хорошей вероятностью нам в другой подсистеме потребуется узнать температуру, ранее записанную в файл или просто хранящуюся где-то в памяти программы, и для такого действия тоже вполне подойдёт идентификатор GetTemperature. К сожалению, не существует универсального рецепта, как избежать таких конфликтов, но кое-что посоветовать всё же можно: выбирая имя для глобально видимого объекта, подумайте, не могло бы такое имя обозначать что-то другое. В рассматриваемом примере для идентификатора GetTemperature можно сразу предложить две-три альтернативные роли, так что его следует признать неудачным. Более удачным мог бы быть, например, идентификатор ScanTemperatureSensor, но лишь в том случае, если он используется для работы со всеми температурными датчиками, с которыми имеет дело ваша программа — например, если такой датчик заведомо единственный, либо если функция ScanTemperatureSensorполучает на вход номер или другой идентификатор датчика. Если же ваша функция предназначена для измерения, к примеру, температуры в салоне автомобиля, причём существует ещё и датчик, скажем, температуры охлаждающей жидкости в двигателе, то в имя функции следует добавить ещё одно слово, чтобы полученное имя идентифицировало происходящее однозначно, например: ScanCabinTemperatureSensor.
2.15.8. Регистр букв, ключевые слова и идентификаторы
Одна из особенностей Паскаля — его принципиальная нечувствительность к регистру букв: один и тот же идентификатор можно написать, как myname, MYNAME, MyName, mYnAmE и так далее. То же самое касается и ключевых слов: begin, Begin, BEGIN, bEgIn... компилятор всё стерпит.
Тем не менее, наиболее распространено мнение, что ключевые слова следует писать в нижнем регистре (т. е. маленькими буквами) и не придумывать на эту тему ничего лишнего. Из этого правила можно сделать одно вполне логичное исключение: написать большими буквами те BEGIN и END, которые обрамляют главную часть программы.
Иногда можно встретить программы на Паскале, в которых ключевые слова написаны с большой буквы: Begin, End, If и т. д.; попадаются также программы, в которых с большой буквы написаны только названия управляющих операторов (If, While, For, Repeat), а все прочие, включая begin и end, пишутся в нижнем регистре. Всё это допустимо, хотя и экзотично; необходимо только чётко сформулировать для себя правила, в каких случаях как мы пишем ключевые слова, и неукоснительно следовать им во всей программе.
Совсем редко можно встретить текст, где все ключевые слова набраны заглавными буквами. Как показывает практика, такой текст читается тяжелее; следовательно, так писать не надо. Ну и, естественно, не надо прибегать к изыскам вроде BeGiN или, скажем, FunctioN — такое тоже встречается, но относится к области бессмысленного позёрства.
Что касается выбора имён для идентификаторов, то в Паскале сложились определённые традиции на эту тему. Если имя переменной состоит из одной буквы или представляет собой короткую аббревиатуру (что вполне допустимо для локальных переменных, см. § 2.15.7), имя такой переменной обычно пишут маленькими буквами: i, j, t, tmp, res, cnt и т. п. Если же имя переменной (а равно имя типа, процедуры или функции, константы, метки и т. д.) состоит из нескольких слов, то эти слова записывают слитно, начиная каждое с большой буквы: StrangeGlobalVariable, ListPtr, UserListltem, ExcellentFunction, KillThemAll, ProduceSomeCompleteMess и т. п. Остаётся вопрос, как быть с именами, представляющими собой одно слово; мы в нашей книге писали их в нижнем регистре (counter, flag, item), но многие программисты предпочитают писать их с большой буквы (Counter, Flag, Item); иногда короткие имена переменных и типов пишут с маленькой буквы, а имена функций и процедур — с большой. Как обычно в таких случаях, выбор за вами.
2.15.9. Как справиться с секциями описаний
Стандарт Паскаля требует жесткого порядка следования секций описаний, но, к счастью, существующие реализации этому требованию не следуют, позволяя располагать секции описаний в произвольном порядке и создавать больше одной секции любого типа — в частности, не обязательно ограничиваться только одной секцией описания переменных.
Всё это даёт возможность отличать настоящие глобальные переменные от переменных, которые нужны в главной части программы, но к которым при этом не нужен доступ из подпрограмм. Например, если в главной части присутствует цикл и для него нужна целочисленная переменная цикла, то, за неимением лучшего, описывать такую переменную придётся в секции описаний переменных, относящейся ко всей программе, однако совершенно ясно, что никакого отношения к глобальным переменным она не имеет. В связи с этим будет лучше, если всё, что нужно в главной части программы и только в ней — переменные, метки, иногда типы, которые не используются нигде, кроме главной части — следует описать непосредственно перед словом begin, обозначающим начало главной части, т. е. после всех описаний подпрограмм. Если вам нужны настоящие глобальные переменные — то есть такие, доступ к которым осуществляется из более чем одной подпрограммы, либо из главной программы и подпрограммы — то для их описания следует создать ещё одну секцию var, на этот раз перед описаниями подпрограмм.
Заметим, что переход между частями программы по меткам невозможен, так что метки, используемые в подпрограммах, должны в них же и описываться, тогда как метки, описываемые в глобальной секции описания меток, должны предназначаться для главной программы. Следовательно, если в главной программе используются метки, секция их описаний должна находиться непосредственно перед началом главной программы.