Программирование: введение в профессию. 1: Азы программирования - 2016 год
Файлы - Язык Паскаль и начала программирования
2.12.1. Общие сведения
Мы уже успели немного поработать с файлами через стандартные потоки ввода и вывода, полагаясь на то, что нужный файл нам “подсунет” пользователь при запуске нашей программы, перенаправив ввод или вывод средствами командного интерпретатора. Конечно, программа и сама может работать с файлами, лишь бы ей хватило на это полномочий.
Для того, чтобы работать с содержимым файла, его нужно открыть. При этом программа обращается к операционной системе, заявляя о намерении начать работу с файлом; обычно при этом указывается, какой файл интересует нашу программу (т. е. задаётся имя файла) и что программа собирается с ним делать (режим работы с файлом — только для чтения, только для записи, для чтения и записи, для добавления в конец). После того как файл успешно открыт, нашей программе наряду с уже знакомыми нам стандартными потоками ввода-вывода становится доступен новый поток ввода или вывода, связанный с файлом на диске, указанным при его открытии. Операции, которые можно проделывать с таким потоком, в целом схожи (а на уровне операционной системы — попросту совпадают) с теми, которые мы можем выполнять со стандартными потоками: в основном это, конечно, уже известные нам чтение и запись, хотя есть и другие.
Потоки ввода-вывода, связанные с вновь открывающимися файлами, нужно как-то отличать друг от друга и от стандартных потоков. Язык Паскаль для этого предусматривает так называемые файловые переменные; для описания таких переменных имеется целое семейство особых файловых типов. Следует отметить, что файловый тип существенно отличается от других типов; самое заметное отличие состоит в том, что переменные файлового типа представляют собой единственный вариант выражения файлового типа, то есть значения файлового типа существуют только в виде “чего-то, что как-то там хранится в файловых переменных”, и более никак; их даже нельзя присваивать. Передавать файловые переменные в подпрограммы можно только через var-параметры. Это может показаться непривычным, ведь раньше мы всегда говорили о значениях заданного типа и выражениях, вычисление которых даёт такие значения, а переменные того же типа рассматривали просто как хранилище соответствующего значения. С файловыми типами всё наоборот: у нас есть только файловые переменные; мы можем догадываться, что в них что-то хранится, и даже говорить, что, наверное, в них хранится “значение файлового типа”, но все эти разговоры будут не более чем отвлечённой философией, поскольку никаких средств работы с такими значениями в отрыве от хранящих их переменных в Паскале нет и не предвидится.
Иначе говоря, переменные файловых типов позволяют нам различать между собой любое количество одновременно активных (открытых) потоков ввода-вывода, но и только: больше мы ни для чего файловые переменные использовать не можем.
В зависимости от того, как мы собираемся работать с файлом, мы должны выбрать конкретный тип файловой переменной. Здесь у нас есть три возможности:
• работать с файлом, предполагая, что он текстовый; для этого используется файловая переменная типа text;
• работать с файлом как с абстрактной последовательностью байтов, имея возможность записать и прочитать любой его фрагмент с помощью так называемых операций блочного чтения и блочной записи; при этом потребуется файловая переменная, тип которой так и называется file;
• предположить, что файл состоит из блоков информации фиксированной длины, которые соответствуют машинному представлению в памяти значений какого-то типа; здесь нам потребуется так называемый типизированный файл, для которого Паскаль поддерживает целое семейство типов, вводимых пользователем, например file of integer, file of real или (чаще) file of myrecord, где myrecord — имя описанного ранее типа-записи.
Отметим, что с одним и тем же файлом мы можем при желании работать по меньшей мере двумя, а часто и всеми тремя из перечисленных способов; избираемый нами способ работы зависит больше не от файла, а от решаемой задачи.
Вне зависимости от того, какого типа мы используем файловую переменную, перед началом работы с файлом необходимо назначить этой переменной какое-то имя файла; это делается вызовом процедуры assign. Например, если мы хотим работать с текстовым файлом data.txt, находящимся в текущей директории, нам в секции описания переменных придётся написать что-то вроде
![]()
а где-то в программе — вызов
![]()
Подчеркнём, что такой вызов просто связывает имя ’data.txt’ с файловой переменной. Процедура assign не пытается ни открыть файл, ни даже проверить, существует ли он (что и понятно, ведь, возможно, мы как раз собираемся создать новый файл). В качестве имени файла можно использовать, разумеется, не только константы, но и любые выражения типа string; если имя начинается с символа “/”, то оно рассматривается как абсолютное имя файла и будет отсчитываться от корневого каталога нашей системы, если же имя начинается с любого другого символа, оно считается относительным и отсчитывается от текущей директории; впрочем, это уже обусловлено не Паскалем, а операционными системами семейства Unix.
Поскольку у начинающих часто возникает путаница между именем файла и именем файловой переменной, подчеркнём ещё раз, что это две совершенно разные, изначально никак не связанные между собой сущности. Имя файла — это то, как он (то есть файл) называется на диске, под каким именем его знает операционная система. Когда мы пишем программу, мы можем вообще не знать, каково будет имя файла во время её работы: возможно, имя файла нам укажет пользователь, или мы получим его ещё из каких-то источников, возможно даже, что мы его прочитаем из другого файла; в реальных задачах такое часто случается.
С другой стороны, имя файловой переменной — это имя переменной и ничего более. Мы вольны называть свои переменные как нам вздумается; если мы переименуем переменные, но ничего больше в программе не изменим, то и поведение нашей программы не изменится, поскольку имена переменных на это поведение никак не влияют36. И, конечно же, выбранное нами имя файловой переменной никак не связано с тем, какой файл из хранящихся на нашем диске мы будем использовать.
Связь между именем файловой переменной и именем файла на диске начинает существовать только после вызова процедуры assign; больше того, никто не запрещает вызвать эту процедуру снова, разрушив старую связь и установив новую.
После того, как файловой переменной назначено имя файла, мы можем попытаться открыть файл для дальнейшей работы с ним. Если мы собираемся читать информацию из файла, то открывать его следует с помощью процедуры reset; в этом случае файл должен уже существовать (если его не существует, произойдёт ошибка), и работа с ним начнётся с его начальной позиции, то есть первая операция чтения извлечёт данные из самого начала файла, следующая операция извлечёт следующую порцию данных и т. д. Альтернативный вариант открытия файла — с помощью процедуры rewrite. В этом случае файл не обязан существовать: если его нет, он будет создан, если же он уже есть, то вся информация в нём будет уничтожена, работа начнётся “с чистого листа”. Текстовые файлы, кроме того, можно открыть на добавление, это делается с помощью процедуры append; для типизированных и блочных файлов эта процедура не работает.
Нужно учесть, что операция открытия файла всегда чревата ошибками, а встроенная диагностика, которую умеет вставлять в наши программы компилятор Free Pascal, отличается феерической невнятностью; поэтому крайне желательно отключить встроенную обработку ошибок ввода-вывода, указав в программе уже знакомую нам директиву {$I-}, и организовать обработку ошибок самостоятельно, используя значение переменной IOResult.
Для чтения и записи текстовых и типизированных файлов используются уже знакомые нам операторы read и write, причём для текстовых (но не для типизированных) файлов можно использовать также и readln, и writeln; отличие здесь лишь в том, что, работая с файлами, а не со стандартными потоками ввода-вывода, первым аргументом в этих операторах мы указываем файловую переменную. Например, если у нас есть файловая переменная f1 и переменная х типа integer, мы можем написать что-то вроде
![]()
причём если f1 имеет тип text, то в соответствующий файл будет записано текстовое представление числа, хранящегося в х (то есть последовательность байтов с кодами символов-цифр), тогда как если f1 — типизированный файл, то записано будет ровно два байта — машинное представление числа типа integer. Точно так же применяются знакомые нам функции eof и SeekEof(последняя — только для текстовых файлов): при работе с файлами эти процедуры принимают один аргумент — файловую переменную, так что мы можем написать что-нибудь вроде “while noteof(f1) do”.
Для работы с блочными файлами read и write не годятся, вместо них используются процедуры BlockRead и BlockWrite, которые мы рассмотрим позже в параграфе, посвящённом этому типу файлов.
Когда работа с файлом окончена, его следует закрыть вызовом процедуры close. Файловую переменную можно после этого использовать дальше для работы с другим (или даже тем же самым) файлом; если после закрытия файла сделать reset или rewrite с той же самой файловой переменной, будет открыт файл с тем же самым именем37, но можно переназначить имя, повторно вызвав assign.
В заключение вводного параграфа приведём текст программы, записывающей всё ту же фразу Hello, world! в текстовый файл hello.txt:

После запуска такой программы в текущем каталоге появится файл hello.txt размером 14 байт (13 символов сообщения и перевод строки), который можно просмотреть, например, с помощью команды cat:

Вообще-то правильнее, конечно, было бы сделать чуть-чуть аккуратнее:

причём первое сообщение об ошибке гораздо важнее, чем второе: файлы очень часто не открываются по совершенно не зависящим от нас причинам, тогда как если файл открылся, то в большинстве случаев запись в него пройдёт успешно (хотя, конечно, не всегда: например, на диске может кончиться место).
Открытый файл, если это простой файл на диске, характеризуется текущей позицией, которая обычно при открытии устанавливается на начало файла, а при открытии текстового файла с помощью процедуры append — на его конец. Каждая операция ввода или вывода сдвигает текущую позицию вперёд на столько байтов, сколько было введено или выведено. Поэтому, например, последовательные операции чтения из одного и того же файла прочитают не одни и те же данные, а последовательно порции данных, находящиеся в файле, одну за другой. В некоторых случаях текущую позицию открытого файла можно изменить.
2.12.2. Текстовые файлы
Как следует из названия, текстовый файл — это файл, содержащий в себе текст, или, точнее, данные в текстовом формате38. Можно сказать, что данные к таком файле представляют собой некий поток символов, иногда разделяемый переводами строки; именно в таком формате мы читаем данные из стандартного потока ввода и выдаём их в стандартный поток вывода.
Для работы с текстовыми файлами, как уже говорилось, применяются файловые переменные встроенного типа text; только для таких потоков ввода-вывода определено понятие строки, что делает осмысленным применение операторов writeln и readln, а также функции eoln (end of line), которая возвращает истину, если в текущей позиции в данном файле находится конец строки. Остальные типы файлов не состоят из строк, так что ни вывод с переводом строки, ни ввод до конца строки, ни собственно конец строки для них не имеют смысла.
Важно понимать, что, если речь идёт не о символах и строках, а о данных других типов — например, о числах — то операция вывода в текстовый файл подразумевает перевод из машинного представления в текстовое, а операция ввода — перевод из текстового представления в машинное. Если это не совсем понятно, перечитайте § 1.6.6, причём прямо сейчас; если сложности не исчезли, обратитесь к кому-нибудь, кто сможет вам всё объяснить. Различие между текстовым и машинным представлением (в частности, для чисел) должно быть для вас совершенно очевидным; если это не так, дальше идти бессмысленно.
В частности, в § 1.6.6 мы рассматривали файлы, содержащие сто целых чисел от 1000 до 100099, каждое на 1001 больше предыдущего, причём файл numbers.txt содержал эти числа в текстовом представлении, а файл numbers.bin — в машинном, которое мы на тот момент называли бинарным. Программа, создающая первый из этих файлов, могла бы выглядеть так:


Текстовые файлы не допускают принудительного изменения текущей позиции и не предполагают попеременных операций чтения и записи; такие файлы записывают целиком, от начала к концу, иногда в несколько приёмов (в этом случае файл открывается на добавление с помощью append), но никогда не возвращаются при этом назад. Если потребовалось что-то изменить в начале или в середине существующего текстового файла, его перезаписывают весь целиком. Поэтому для текстовых файлов процедура reset открывает файл в режиме “только чтение”, а процедуры rewrite и append — в режиме “только запись”.
Особенности текстового представления данных требуют дополнительной осторожности при выполнении чтения “до конца файла”. Подробное обсуждение этого мы уже приводили в § 2.7.4 для случая стандартного потока ввода; при чтении из обычного текстового файла возникают аналогичные проблемы, решаемые с помощью той же самой функции SeekEof, только в этом случае она вызывается с одним параметром, в качестве которого ей передаётся файловая переменная. Напомним, что функция SeekEof фактически проверяет, есть ли ещё в потоке значащие (непробельные) символы; для этого она прочитывает и отбрасывает все пробельные символы, и если в процессе этого чтения/отбрасывания возникает ситуация “конец файла”, функция возвращает “истину”, если же найден значащий символ, этот символ возвращается обратно в поток (считается непрочитанным, чтобы его использовал последующий read), а сама функция при этом возвращает “ложь”. Предусмотрена “файловая” версия также и для функции SeekEoln, которая аналогичным образом “ищет” конец строки, т. е. проверяет, можно ли из текущей строки прочитать ещё что-то значимое.
Пусть, к примеру, у нас имеется текстовый файл, имя которого мы получим через аргумент командной строки; файл состоит из строк, в каждой из которых располагаются одно или несколько чисел с плавающей точкой. Числа, находящиеся в одной строке, нам нужно будет перемножить, а результаты этих умножений — сложить и вывести результат. Например, для файла, содержащего
![]()
результатом работы должно стать число 36.0. Соответствующую программу можно написать так:

Обратите внимание на readln(f) после цикла чтений/умножений. Он вставлен для того, чтобы изъять из потока ввода символ перевода строки; если этот оператор убрать, программа просто “зависнет”.
Ясно, что функции SeekEof и SeekEoln можно применять только для текстовых файлов; для любых других форматов данных такие функции просто не имеют смысла, ведь и разделение данных пробелами, и разнесение данных на разные строки — это, очевидно, явления, возможные только при работе с текстовым представлением.
Стоит отметить, что потоки стандартного ввода к стандартного вывода тоже имеют свои имена — для них Free Pascal предусматривает глобальные переменные, имеющие тип text. Поток стандартного вывода можно упомянуть по имени output; например, writeln(output, ’Hello’) — это то же самое, что к просто writeln(’Hello’). Аналогично, поток стандартного ввода обозначается именем input, так что можно написать read(input, х) вместо просто read(x). Эти переменные могут быть удобны, например, если вы пишете какую-то подпрограмму, которая будет выдавать данные в текстовом виде, но не знаете заранее, нужно ли будет выдавать эти данные в текстовый файл или в стандартный поток; в этом случае можно предусмотреть параметр типа text, в качестве которого передавать или открытую файловую переменную, или output.
Под влиянием языка Си во Free Pascal вошли также другие названия глобальных переменных, обозначающих стандартные потоки: stdin (тоже, что и input) и stdout (то же, что и output). Кроме того, Free Pascal позволяет осуществить вывод в стандартный поток выдачи сообщений об ошибках (см. § 1.4.9), также называемый потоком диагностики, который обозначается как ErrOutputили stderr.
2.12.3. Типизированные файлы
Под типизированным файлом в Паскале понимается файл, содержащий последовательность записей одинакового размера, соответствующих машинному представлению значений какого-то типа. Например, файл numbers.bin, который использовался в § 1.6.6, можно рассматривать как состоящий из 100 записей по четыре байта каждая, соответствующих машинному представлению четырёхбайтного целого (тип longint). Следующая программа создаст такой файл:

Если сравнить эту программу с программой GenerateNumTxt из предыдущего параграфа, можно обнаружить, что в тексте почти ничего не изменилось: поменялось название программы, суффикс в имени файла (.bin вместо .txt), используется оператор write вместо writeln и, наконец, самое главное: файловая переменная в предыдущей программе имела тип text, а в этой — fileof longint.
В принципе, файл может состоять из записей, имеющих практически любой тип, нельзя только использовать файловые типы; настоятельно не рекомендуется (хотя и возможно) использовать указатели, которые мы будем рассматривать в следующей главе. Из данных любого другого типа файл состоять может; в частности, используя тип file of char, можно открыть в качестве типизированного текстовый файл, да и вообще любой, ведь любой файл состоит из байтов.
Очень часто в роли типа записи в типизированном файле используется, собственно, запись (record). Например, создавая какую-нибудь программу для работы с топографическими картами, мы могли бы задействовать файл, содержащий точки на местности, заданные широтой и долготой и снабжённые названиями. Для этого можно было бы описать такой тип:

и соответствующую файловую переменную:
![]()
Для создания такого файла можно воспользоваться процедурой rewrite, для открытия существующего — процедурой reset. Операции открытия на добавление для типизированных файлов не предусмотрено.
В отличие от текстовых файлов, которые состоят из строк разного размера, записи типизированных файлов имеют фиксированный размер, что позволяет чередовать операции чтения и записи в любые места существующего файла. Изменить текущую позицию в открытом типизированном файле можно с помощью процедуры seek, которой нужно передать два параметра: файловую переменную и номер записи (при этом самая первая запись в файле имеет номер 0). Например, следующие две строки:
![]()
запишут запись rес в позицию № 15, вне зависимости от того, с какими позициями файла мы работали до этого. Это можно использовать для изменения отдельных записей уже существующего файла, что особенно важно для файлов значительного объёма, поскольку позволяет обойтись без их перезаписи. Пусть, к примеру, у нас есть файл, состоящий из записей NamedPoint, и нужно взять из этого файла запись с номером 705 и поменять её имя (то есть значение поля name) на строку ’Check12’. Для этого мы можем прочитать эту запись в переменную типа NamedPoint(будем считать, что такая переменная у нас есть и называется np), изменить значение поля name и записать полученную запись на то же место:
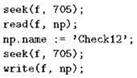
Обратите внимание, что перед записью нам пришлось опять применить seek; дело в том, что после операции чтения текущая позиция в открытом файле f стала соответствовать записи, следующей за прочитанной, то есть в данном случае — записи № 706, и пришлось это исправить.
Поскольку типизированные файлы позволяют чередовать операции чтения и записи, по умолчанию процедуры, открывающие типизированный файл, открывают его в режиме “чтение и запись”. Это касается и reset, и rewrite: различие между ними только в том, что rewrite создаёт новый файл, а если файл с таким именем уже есть, то ликвидирует его старое содержимое; resetне делает ни того, ни другого, а если файла с таким именем не было, выдаётся ошибка.
Такой подход может создать проблемы, например, при работе с файлом, который программа должна только прочитать, при этом для его записи у программы недостаточно полномочий. В такой ситуации попытка открыть файл для чтения и записи окончится неудачей, то есть как reset, так и rewrite выдаст ошибку. Решить проблему позволяет глобальная переменная, которая называется filemode; по умолчанию она содержит значение 2, означающее, что типизированные файлы открываются на чтение и запись. Если в эту переменную записать число 0, то файлы будут открываться в режиме “только чтение”, что позволит (с помощью процедуры reset) успешно открыть файл, на запись которого у нас прав нет, но есть права на чтение; конечно, такой файл мы сможем только читать. Очень редко встречается ситуация, когда у нас есть права на запись в файл, но нет возможности чтения. В этом случае нужно занести в переменную filemodeзначение 1 и для открытия файла использовать rewrite.
2.12.4. Блочный ввод-вывод
Наряду с текстовыми и типизированными файлами Free Pascal поддерживает так называемые нетипизированные файлы, позволяющие производить чтение и запись сразу большими порциями. В оригинальном Паскале такого средства не было, но именно такой вариант лучше всего соответствует возможностям, которые для работы с файлами предусмотрены в современных операционных системах.
Информацию, читаемую из нетипизированного файла, можно разместить в произвольной области памяти, то есть для этого подойдёт практически любая переменная; то же самое можно сказать и про запись в нетипизированный файл: информацию для такой записи можно взять из переменной произвольного типа. При открытии нетипизированного файла указывается размер блока в байтах, а при чтении и записи — количество блоков, которые нужно прочитать или записать. Чаще всего в качестве размера блока указывается число 1, что позволяет производить чтение и запись совершенно произвольными фрагментами.
Файловая переменная для блочного ввода-вывода должна иметь тип file без указания типа элементов:
![]()
Как и для файлов других типов, для нетипизированных файлов назначается имя с помощью процедуры assign, а открываются они с помощью уже знакомых нам reset и rewrite, но у этих процедур при работе с нетипизированными файлами появляется второй параметр — целое число, означающее размер блока. Очень важно про этот параметр не забывать, поскольку “по умолчанию” (то есть если забыть указать второй параметр) размер блока будет принят равным 128 байтам, что обычно не соответствует нашим целям. Почему принято именно такое “умолчание”, непонятно; как мы уже отмечали, чаще всего используется размер “блока” в один байт, как наиболее универсальный.
Точно так же, как и в случае типизированных файлов, обе процедуры reset и rewrite по умолчанию пытаются открыть файл в режиме “чтение и запись”; на это можно повлиять, изменяя значение глобальной переменной filemode, как это описано в предыдущем параграфе.
Для чтения из нетипизированных файлов и записи в них используются процедуры BlockRead и BlockWrite, которые очень похожи друг на друга: обе получают по четыре параметра, причём первым параметром указывается файловая переменная, вторым параметром — переменная произвольного типа и размера (за исключением файловых переменных), в которую будет помещена информация, прочитанная из файла, либо из которой будет взята информация для записи в файл (для BlockRead и BlockWrite соответственно). Третий параметр — целое число, задающее количество блоков, которые следует соответственно прочитать или записать; естественно, произведение этого числа на используемый размер блока ни в коем случае не должно превосходить размер переменной, заданной вторым параметром. Наконец, в качестве четвёртого параметра процедурам передаётся переменная типа longint, int64, word или integer, и в эту переменную процедуры записывают количество блоков, которое им реально удалось прочитать или записать. Этот результат может в общем случае оказаться меньше того, что мы ожидали; чаще всего так происходит при чтении, когда в файле осталось меньше информации, чем мы пытаемся прочитать. Например:

Очень важен для нас один особый случай, который происходит только при использовании BlockRead: если в переменной, указанной последним параметром, после вызова функции оказалось значение 0, это означает наступление ситуации “конец файла”.
В принципе, четвёртый параметр можно не указывать, тогда любое несоответствие результата ожиданию вызовет ошибку. Делать так настоятельно не рекомендуется, в особенности при чтении: в самом деле, если в файле осталось недостаточно данных или если достигнут его конец, ничего ошибочного в этом нет, к вообще работа с использованием четвёртого параметра позволяет писать программы более гибко.
Для примера рассмотрим программу, которая копирует один файл в другой, получив их имена из параметров командной строки. Как для исходного, так и для целевого файлов (англ. source и destination) мы будем использовать нетипизированные файловые переменные; первый файл мы откроем в режиме “только чтение”, второй — в режиме “только запись”. Чтение мы будем производить фрагментами по 4096 байт (4Кb), причём этот размер вынесем в константу; в качестве буфера, то есть переменной, в которую помещается прочитанная информация, воспользуемся массивом соответствующего размера из элементов типа byte.
Записывать в целевой файл мы будем на каждом шаге ровно столько информации, сколько было прочитано из исходного. Наконец, при возникновении ситуации “конец файла” мы немедленно завершим цикл чтения/записи, причём сделать это нам придётся до выполнения записи, то есть из середины тела цикла; мы воспользуемся для этого оператором break, а сам цикл сделаем “бесконечным”. После завершения цикла мы, естественно, должны будем закрыть оба файла. Поскольку мы уже знаем о существовании переменной ErrOutput, обозначающей поток сообщений об ошибках, все такие сообщения будем выдавать, как положено, именно в этот поток. Завершать программу после обнаружения ошибок будем с кодом 1, чтобы показать операционной системе, что у нас что-то пошло не так. Полностью программа будет выглядеть так:


2.12.5. Операции над файлом как целым
Над файлом как единым объектом можно выполнить несколько операций, наиболее важные и востребованные из которых — это удаление и переименование. Для этого в Паскале предусмотрены процедуры erase и rename.
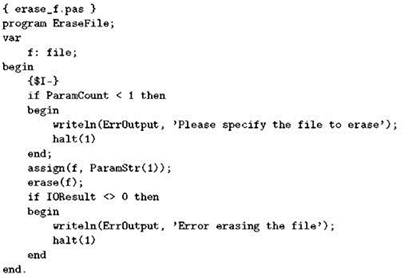
Процедура erase получает один параметр — файловую переменную произвольного типа, то есть здесь подойдёт и типизированный файл, и переменная типа file или text. К моменту вызова eraseфайловой переменной должно быть назначено имя файла с помощью assign, но файл при этом не должен быть открыт, то есть после выполнения assign мы должны либо вообще не вызывать reset, rewrite или append, либо, открыв файл и поработав с ним, закрыть его с помощью close. Например, следующая простая программа удаляет с диска файл, имя которого задано параметром командной строки:
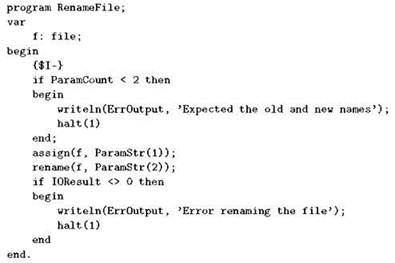
Процедура rename получает два параметра: файловую переменную и новое имя для файла (в виде строки). Как и в случае с erase, файловая переменная может иметь любой из файловых типов, а на момент вызова rename ей должно быть назначено имя файла с помощью assign, но файл не должен быть открыт. Следующая программа получает два аргумента командной строки — старое и новое имена файла, и соответствующим образом переименовывает файл: